Could we hack it? LCAB stats group’s first hackathon
Posted on Monday 3 February 2025
After a chapter-by-chapter work through of the excellent Statistical Rethinking the LCAB stats group needed a new format and a new challenge. Now as pro-level Bayesian statistical modellers we were itching for an encounter with real data in the wild. The solution: mini-hackathons!
What is a hackathon you may say. The premise has been spreading since the 2000s: a group of workers, usually software developers or engineers with otherwise diverse skill sets, seclude themselves away for a period of time to try to attack a well-specified technical problem. The goal is to emerge with a working prototype - or in this case, analysis - that can be built on and rolled out in future. The concept is growing in the environmental sciences with hackathon events being run by organisations such as the British Ecological Society.
The event started well, after a brief discussion of the relative merits of smooth versus crunchy peanut butter we got to work on selecting a question. As there was quite a bit of interest in species distribution models (SDM) we chose to use this family of models to identify which European species might be gained by the UK under a changing climate. To do this we needed species, climate and land-use data as a minimum, and some way to do an SDM.
After a brief discussion (which yielded interesting facts such as Kian’s revelatory fact that the European Tree Frogs don’t live in trees and Becci’s in depth knowledge of introduced snakes in Wales), we set about downloading species presence records from GBIF.org. Brennen started to look at CHELSA to get our climate data and Rosie explored “land-system” data. Kian hit a few bumps when his laptop showed its age and refused to download any data but Jonny soon brought his excessive 64Gb of RAM to the task. Jack looked into SDM methods. After resisting the temptations of fancy new models with words such as “Gaussian process” and “additive Bayesian” we decided to try the commonly used ensemble model of biomod2. With the SDM pipeline coming together we started to pool our prepared data and felt that sinking feeling as the sheer size of the data slowed our progress.
Did we get a working model? Well, no. But we all learnt about SDMs, climate simulations, processing land-system data, and it was an introduction to hackathons for some. We also have an analysis pipeline that we will continue to build on in sessions over the coming year, so watch this space for projections of Asian hornets coming soon to your area…
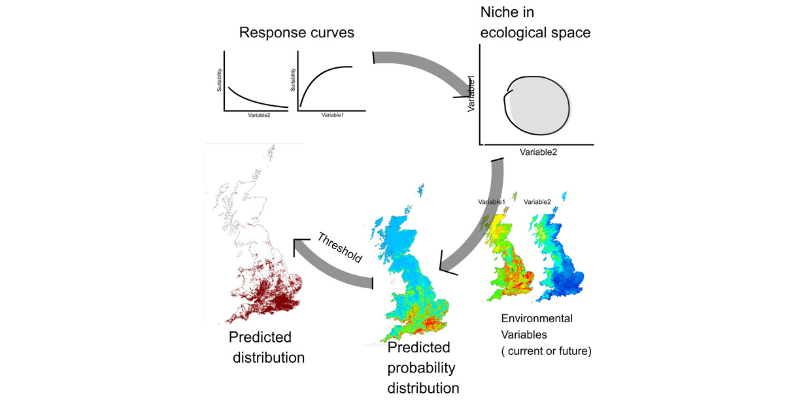
Lead image: Working principle of mechanistic species distribution models via Wikimedia Commons by Thejoyforever, CC BY-SA 3.0