School of Physics, Engineering and Technology
Continuous online adaptation in many-core systems: from graceful degradation to graceful amelioration
![]()
Members: Dr. Gianluca Tempesti (PI) (York), Dr. Martin Trefzer (York), Prof. Andy Tyrrell (York), Dr. Nizar Dahir (York), Dr. Pedro Campos (York), Prof. Steve Furber (Manchester), Dr. Simon Davidson (Manchester), Dr. Indar Sugiarto (Manchester), Prof. Bashir Al-Hashimi (Southampton), Dr. Geoff Merrett (Southampton)
Funded by: EPSRC (EP/L000563/1)
Partners: The University of Manchester, University of Southampton
Outline and Approach
Outline
Imagine a many-core system with thousands or millions of processing nodes that gets better and better with time at executing an application, “gracefully” providing optimal power usage while maximizing performance levels and tolerating component failures. Applications running on this system would be able to autonomously vary the number of nodes in use. The GRACEFUL project aims at investigating how such mechanisms can represent crucial enabling technologies for many-core systems.
Specifically, the project focuses on how to overcome three critical issues related to the implementation of many-core systems, as identified in the Many-Core Architectures and Concurrency in Distributed and Embedded Systems workshop organized by the EPSRC in April 2012: reliability, energy efficiency, and online optimisation. The need for reliability is an accepted challenge for many-core systems, considering the large number of components and the increasing likelihood of faults of next-generation technologies, as is the requirement to reduce the heat dissipation related to energy consumption. online optimisation, on the other hand, is a mechanism that could be vital to enable the implementation of these properties in systems where several parameters (e.g. number of available cores, power profile, substrate defects and online faults) cannot be known at compile time and cannot be managed centrally due to the vast number of cores involved. The 2011 ITRS roadmap strongly supports these considerations.
The approach is centred around two basic processes: Graceful degradation implies that the system will be able to cope with faults (permanent or temporary) or potentially damaging power consumption peaks by lowering its performance. Graceful amelioration implies that the system will constantly seek for alternative implementations that represent an improvement from the perspective of some user-defined parameter (e.g. execution speed, power consumption).
Approach
The project will combine novel fault tolerance and optimisation methods (which can be optimisation of functional performance but also of power consumption, area, etc.) using a set of background mechanisms that run concurrently with the applications, making use of spare cores (of which in a many-core system there will be significant numbers) to monitor and fix/optimize the operational cores. Thus, an application that runs rarely will be largely ignored but one that runs often will slowly become more and more optimized.
The basic scenario we will consider is that of an application running on a system consisting of many, possibly heterogeneous, processor cores. While acknowledging the fundamental importance of software compilation techniques, the project will focus on the hardware aspects of a many-core system, assuming that the application has been pre-parallelized by the user and starting the investigation from the output stage of the compiler. Each core will then handle a specific subprogram, or task, within the application.
On the implementation side, we will deploy our system on two platforms. To demonstrate the “immediate” advantages of the approach, we will implement a software-based solution to the SpiNNaker system, probably the machine that most closely approximates a many-core system currently available in the UK. Using conventional ARM cores, this implementation will illustrate how the features of the proposed approach can impact current technology.
To more fully investigate the advantages of our system and to analyse the fundamental trade-off between homogeneous and heterogeneous systems (a crucial issue in many-core research), the second platform will consist of a set of custom FPGA-based boards. While the development of a custom IC would allow greater scope for our investigations (and remains an option for a continuation project in the future), the exploratory nature of this project is better suited to a programmable logic device, which will allow us freedom to investigate alternative node architectures. The design of custom boards will allow us to introduce complex power measurement and management components that are not available in off-the-shelf solutions.
Implementation strategy
Implementation strategy
The proposed implementation approach relies on the observation that, in a many-core system, the abundance of resources implies that not all cores will be used for the execution of applications. The overall operation of the system (Figure 1) will rely on four different kinds of units (in addition to the empty nodes, currently not used but at the disposal of the application):
Application Units (AU) represent the “conventional” processing nodes running the target application. These could be conventional processors (e.g. ARM cores in SpiNNaker) or dedicated units containing programmable logic. If the latter, the Optimization Units will explore hardware/software trade-offs to seek improved implementations.
Monitoring Units (MU) will monitor and profile the execution of the AUs and, if necessary, take steps to resolve issues. Monitoring will be carried out according to user-specified parameters: in this project, we will focus specifically on fault tolerance and power consumption, with a lesser emphasis on execution speed, but the general approach could easily be expanded to handle different parameters. They will operate in the background, without affecting the execution of the application unless an issue is detected or an improved implementation is found. The optimal density of MUs (and hence their radius, i.e., the number of monitored AUs) is a parameter that depends on several factors and will be attentively examined in the project. To avoid single points of failure, MUs will also instantiate reciprocal monitoring.
Optimisation Units apply search algorithms to identify alternative implementations of application nodes. They will operate on intermediate code (eg compilation trees) and apply functionally-neutral code transformations and/or hardware/software trade-offs to generate and evaluate Candidate Units. Evolutionary Algorithms (EAs) can be an efficient approach for this kind of search, particularly considering that the optimisation will be implemented as a background process that requires neither a single optimal solution nor a fast reaction time.
Candidate Units, generated by the Optimisation Units, represent alternative implementations of AUs. They are evaluated according to the desired parameters (power consumption, performance, etc.) and, if they represent an improvement over the original nodes, will eventually replace them. The replacement will be handled by the MUs and will be non-disruptive (eg, will occur after the internal states of the nodes have been aligned and at specific and predictable points in the code).
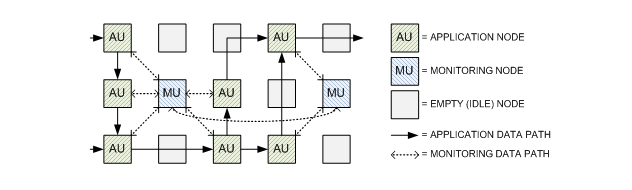
Figure 1: Many-core scenario - Monitoring with radius = 1
To ensure scalability, all units will be physically implemented by the same processing nodes (in other words, the same kind of hardware processors) and all interactions will be local, with no centralized control. To more closely model a probable scenario in future many-core systems, the general structure of nodes will be based on a processor with a “base” datapath (Core Processing Unit & Local Memory) plus an area of programmable logic, which can be used to optimize performance, by exploiting hardware acceleration and effectively implement heterogeneous systems, and for fault tolerance, by providing alternative computational elements. However, in order to increase the potential impact of the approach, all the mechanisms developed in the project will have a general application to many-core systems that do not include programmable logic, a versatility that will be demonstrated through the dual implementation on the SpiNNaker architecture and on custom processing boards.
Operation
The following example scenarios illustrate the projected operation of the system. These scenarios, by no means exclusive, should illustrate the general operation of the system to be developed in the project. While these seem rather well-defined and worked out, their practical implementation on many-core systems is far from worked out or trivial. Achieving the desired properties will involve the development of novel mechanisms at several levels of the system design cycle, from the output of the compilation process through to the hardware architecture of the nodes and the interconnection network. Achieving these properties in an appropriate way and developing the mechanisms to make them functional is the core of this proposal.
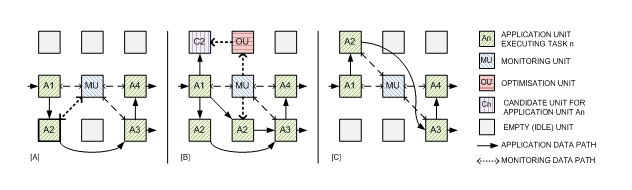
Scenario I (graceful amelioration for performance): A Monitoring Unit [A] detects that one of the Application Units is a bottleneck in the performance of the system (e.g., in [2] this was detected by monitoring I/O FIFOs). If execution speed is a critical factor in the system, the MU can implement a rapid solution by instantiating an identical copy of the slow Application Unit to share the load [2]. At the same time [B], it might generate an Optimisation Unit that will run a search algorithm which will seek alternative implementations for the task. These are tested by running them in parallel to the existing node in one or more Candidate Units. The CUs receive the same input data as the original AU, and their performance is compared. Non-optimal implementations are discarded. If the OU identifies that the candidate node outperforms existing node [C], the original node is discarded, returned to the pool of empty nodes, and replaced by the new one, which contains the same state and can therefore be seamlessly substituted.
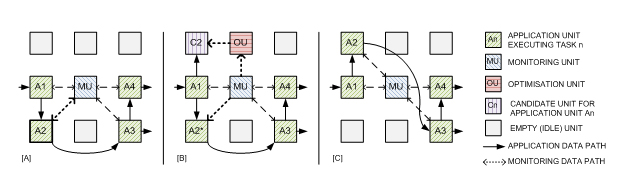
Scenario II (graceful amelioration and degradation for power consumption): A scenario for power consumption could be somewhat similar to the scenario for performance (indeed, the objective of the project is to define general mechanisms that can be applied for the optimization of any parameter). A Monitoring Unit [A] detects that one of the Application Units is exceeding acceptable thresholds of power consumption (spikes due to possible faults or generally high computational load), which could potentially lead to failure. Again, the MU could act in two steps. First, it could act directly on the AU, for example by reducing clock frequency and/or lowering voltage (node A2* in [B]), which could lead to a (graceful) degradation in performance but avoid the risk of catastrophic failures (if the degraded performance is not adequate, Scenario I will then “kick in”, illustrating the seamless interfacing between optimisation scenarios). At the same time, once again an Optimization Unit could be created to seek for alternate implementations of the application task with better power efficiency, using a mechanism identical to the one described for Scenario I, but with a different target for optimisation ([B] and [C]).
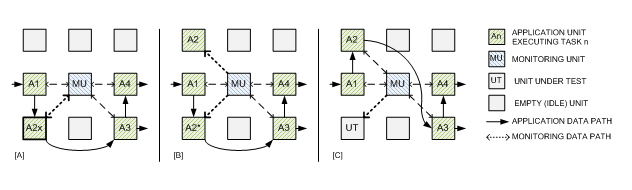
Scenario III (graceful degradation for fault tolerance): This scenario presents a certain number of differences compared to the previous two, in that the presence of a fault could potentially load to immediate catastrophic failure of a node. Once a fault in one of the monitored has been detected by the MU (A2x in the figure [A]), several different options are possible. In this project, our main focus will be on streaming DSP applications, where the loss of information, if temporary, can be deemed acceptable A first reaction of the MU [B] could then be to act on frequency and voltage levels of the node (A2*) to determine whether the fault can be (temporarily) masked and allow computation to continue, albeit at a lower speed (graceful degradation). At the same time, the MU will activate one of the idle units to replace the faulty one, attempt, where possible, to copy and transfer the state of the faulty AU, and, once the process is complete, disable the original node and bring online its replacement [C]. At this stage, the original node can be thoroughly tested and, if deemed fault-free (for example, in case of a non-permanent fault), returned to the pool of idle nodes.