School of Physics, Engineering and Technology
Bio-inspired algorithms: projects
- Continuous online adaptation in many-core systems: from graceful degradation to graceful amelioration
- EPSRC Platform grant: Bio-inspired Adaptive Architectures and Systems
- Molecular Software and Hardware for Programmed Chemical Synthesis
- AlBiNo - Artificial Biochemical Networks: Computational Models and Architectures
- Diagnosis of Neurological Disease using Evolutionary Classifiers
- Intelligent Control in Practice
- Multi-Agent Intelligent Control for the Skylon Launch Vehicle
- Biosequence Motif Discovery using Evolutionary Computation
- nEUro-IT.net Research Directory
- Cartesian Genetic Programming (CGP)
- Implicit Context Representation for Evolutionary Computation
The group carries out a variety of research in the field of evolutionary computing from theory to practice. Particular areas of focus for the group in this area are in Cartesian Genetic Programming, artificial biochemical networks and multi-agent system. Within these areas we concentrate on the methods and the design of evolvable, scalable, biologically-motivated representations. This includes work upon developmental representations, implicit context representations, and multiple chromosome approaches. In addition to our theoretical work, we also have experience of applying evolutionary computation to a variety of real world problems, including robotic control, biological sequence understanding, medical classification, and image processing.
Continuous online adaptation in many-core systems: from graceful degradation to graceful amelioration
![]()
Members: Dr. Gianluca Tempesti (PI) (York), Dr. Martin Trefzer (York), Prof. Andy Tyrrell (York), Dr. Nizar Dahir (York), Dr. Pedro Campos (York), Prof. Steve Furber (Manchester), Dr. Simon Davidson (Manchester), Dr. Indar Sugiarto (Manchester), Prof. Bashir Al-Hashimi (Southampton), Dr. Geoff Merrett (Southampton)
Funded by: EPSRC (EP/L000563/1)
Partners: The University of Manchester, University of Southampton
Outline
Imagine a many-core system with thousands or millions of processing nodes that gets better and better with time at executing an application, “gracefully” providing optimal power usage while maximizing performance levels and tolerating component failures. Applications running on this system would be able to autonomously vary the number of nodes in use. The GRACEFUL project aims at investigating how such mechanisms can represent crucial enabling technologies for many-core systems.
EPSRC Platform grant: Bio-inspired Adaptive Architectures and Systems
Members: Prof AM. Tyrrell, Dr MA. Trefzer, Prof J. Timmis, Dr G. Tempesti
Funded by: EPSRC
Dates: October 2013 - September 2018
Overview
The ever-increasing complexity of highly integrated computing systems requires more and more complex levels of monitoring and control over the potentially large number of interacting resources available in order to manage and exploit them effectively. Technology innovations are driving device and systems design to consider, for example, a move from multi-core (2-10 cores) to many-core (hundreds-thousands of cores) and to design hybrid technology platforms. However, it is still neither obvious how these systems will be constructed architecturally nor how they will be controlled and programmed. Major issues related to these systems include reliability and online optimisation, as well as the efficient utilisation of these complex systems. The need for reliability in such systems is obvious, considering their size and the huge design and test efforts required to manage the increasing sensitivity to faults of next-generation technologies.
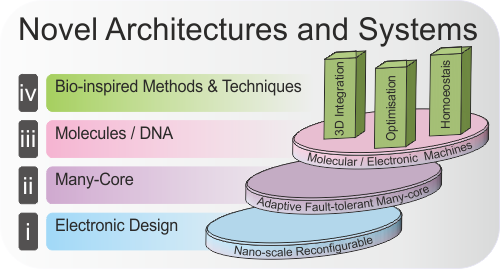
Here we will research into hardware and software systems whose designs are motivated by biological principles. The main activities will be in the design, evaluation and exploitation of such systems. This will concern the advancement of bio-inspired techniques to construct microelectronic systems of the future. This will cover the topology of such systems that will both be massively parallel and will be required to cope with unreliable components, such as the variability of devices resulting from the continuing reduction in feature size. The need for new manufacturing methods such as 3D fabrication and new materials such as molecular devices will be critical for the future of microelectronic system design and will form a significant part of this research.
Objectives
Our long-term objective is to apply biological mechanisms, that are proven to enable stable computation with unreliable components in new nano and/or molecular substrates, in such a way that their key features can be exploited to perform robust computation with a performance that can compete with traditional computing paradigms. We envisage achieving this goal in a number of steps including:
- the development of new methodologies using silicon as an affordable, accessible, state-of-the-art technology, and
- the integration of silicon with other (molecular) technologies in hybrid systems, thereby allowing the shift of more functionality to suitable alternative technologies .
The Platform Grant funding allows us flexibility to bring together current, distinct research threads, adapt to new, emerging areas of research, increase the effectiveness with which these are incorporated to achieve our long-term vision.
Molecular Software and Hardware for Programmed Chemical Synthesis
Members: Andy M. Tyrrell, Cristina Costa Santini
Funded by: EPSRC - EP/F008279/1.
Start Date: October 2008
Molecular Software and Hardware for Programmed Chemical Synthesis
This is a very interdisciplinary project. We intend to design a nanoscale chemical factory in which the machines, like the products, are molecules. The factory will not only build molecules but will be capable of evolving them to have desirable properties. The products will be linear molecules produced by linking together smaller building blocks in a defined sequence - at each stage the molecular machinery will be capable of choosing the correct building block from a range of possibilities. The system will be capable of synthesizing a library of molecules with different sequences and selecting 'successful' molecules for their fitness to perform a specified task. We will also develop designs for more powerful systems in which the molecular machinery responsible for chemical synthesis has internal computing power and can direct its own operation.
The University of York is responsible for coordinating the development of the designs that will show computation, or control.
This part of the project is within the broad area of molecular machines. Specifically, DNA is the molecular substrate being harnessed. DNA is an interesting engineering material (DNA as an engineering material, Turberfield, Physics World, March 2003.), as it can be used to design systems capable of self-assembly, due to the complementarity of the base pairs.
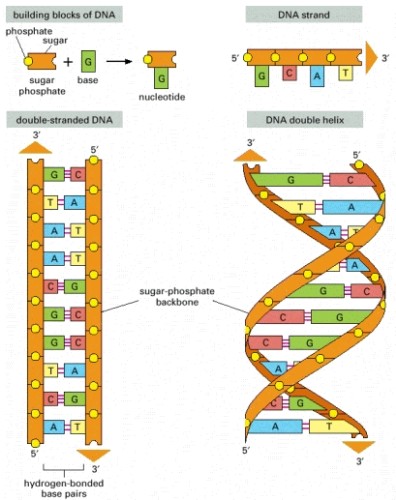
DNA and its building blocks. (From Molecular Biology of the Cell, 4th Edition)
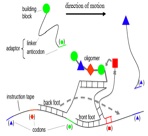
Interesting structures that can be controlled have already been shown, such as the molecular tweezer (A DNA-fuelled molecular machine made of DNA, Yurke et al, NATURE, VOL 406, AUGUST 2000.), that closes in the presence of the ‘closing strand’ and opens in the presence of the ‘opening strand’, as shown in the figure.
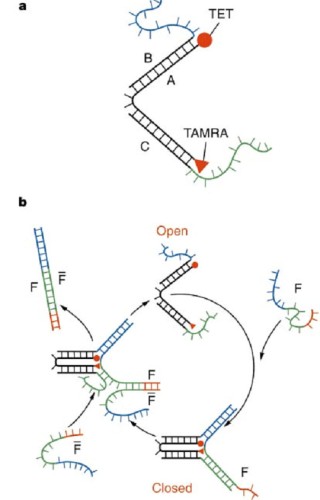
Construction and operation of the molecular tweezers. Molecular tweezer structure formed by hybridisation of oligonucleotide strands A,B and C. By harnessing these characteristics in innovative designs, we aim at a DNA based system that will, for example, perform as a Finite State Machine.
Project Partners
Universities of York, Oxford, Warwick and Southampton.
AlBiNo - Artificial Biochemical Networks: Computational Models and Architectures
![]()
Members: Michael Lones, Luis Fuente, Alex Turner, Andy Tyrrell, Susan Stepney (CS), Leo Caves (Biology)
Funded by: EPSRC
Dates: September 2008 - September 2013
Overview
This project focuses upon one of the most complex sets of structures found in biological systems: biochemical networks. These structures are fundamental to the development, function and evolution of biological organisms, and are the main factor underlying the complexity seen within higher organisms. Previous attempts to build hardware and software systems motivated by these structures have led to a group of computer architectures which we collectively refer to as artificial biochemical network models. The project aims to investigate the space of artificial biochemical network models: contributing to a better understanding of how they work, developing new algorithms and theoretical tools, and applying these methods to real world problems.
Controlling chaotic dynamical systems
In initial work, we have shown how evolved artificial biochemical networks can be used to control complex dynamics in numerical dynamical systems. Our results are promising, showing that relatively simple artificial biochemical networks are capable of state space targeting within both the Lorenz system and Chirikov's standard map – numerical systems located at opposite ends of the dynamical systems spectrum.
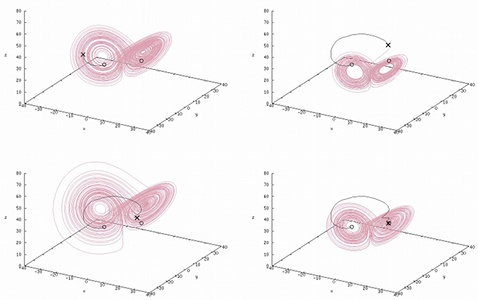
For more details, see:
Lones, M. A., Tyrrell, A. M., Stepney, S. and Caves, L. S. D. “Controlling Complex Dynamics with Artificial Biochemical Networks,” to appear in Proc. European Conference on Genetic Programming (EuroGP) 2010, April 2010.
Robotic locomotion
More recently, we have been looking at how artificial biochemical networks may be used to control locomotion in legged robots. Below are some movies showing dynamic gaits under the control of evolved artificial biochemical networks:

For more details, see:
Lones, M. A., Tyrrell, A. M., Stepney, S. and Caves, L. S. D. “Controlling Legged Robots with Coupled Artificial Biochemical Networks,” Proc. European Conference on Artificial Life (ECAL) 2011, August 2011.
Controlling a hexapod robot
Cell-signalling constitutes the basis of cell development, specialisation and differentiation. Stimuli triggered by signalling cells or an external environment generate a response within target cells by means of a cascade of interacting molecules. The change in chemical concentrations within the cell and genes' expression levels allow new behaviours to emerge. Signalling networks are usually described as chemical reaction based systems, which play a critical function in cellular communication. Such networks are responsible for the transduction of an extra-cellular chemical message into catalytic enzymes which are involved in metabolic networks. The image below depicts an example of signalling network where grey, yellow and green nodes represent its receptors, internal molecules and outputs respectively. Red and blue connections show the possible relations amongst molecules, which are either inhibition or activation.
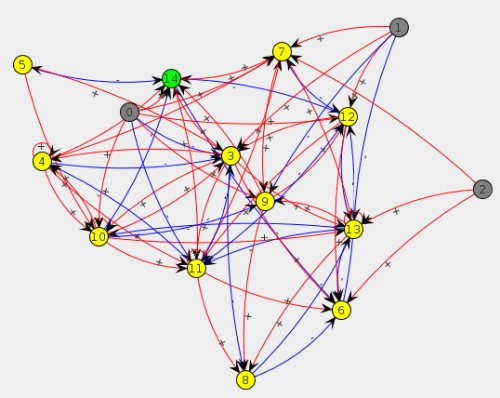
The ultimate aim of the Albino project is to apply these previously simulated signalling networks to the robotic control. Currently, Albino has purchased a hexapod robot equipped with ultrasounds, infrared and pressure sensors. They will feed information into the network receptors triggering molecular reactions which then allow the robot to move.

Hexapod Robot
Events
Special session on artificial biochemical networks at CEC2009
Diagnosis of Neurological Disease using Evolutionary Classifiers

Members: Steve Smith, Michael Lones, David Halliday
Start Date: June 2008
This research uses novel evolutionary algorithms to induce classifiers capable of recognising the symptoms of neurological diseases such as Parkinson's and Alzheimer's. More information can be found in the following publications:
Smith, S. L. and Lones, M. A. “Implicit Context Representation Cartesian Genetic Programming for the Assessment of Visuo-Spatial Ability,” in Proc. 2009 IEEE Congress on Evolutionary Computation, May 2009.
Smith, S.L. et. al. “Diagnosis of Parkinson's Disease using Evolutionary Algorithms,” Genetic Programming and Evolvable Machines, In press, 2007.
Aly, N. M., Playfer, J. R., Smith, S. L. and Halliday, D. M., “A novel computer-based technique for the assessment of tremor in Parkinson's disease,” Age and Ageing, doi:10.1093, June 2007.
Allen, D.P., Playfer, J.R., Aly, N.M.,. Duffey, P., A. Heald, A., Smith, S.L. and Halliday, D.M., "On the use of low-cost computer peripherals for the assessment of motor dysfunction in Parkinson’s disease" IEEE Trans. Neural Systems & Rehabilitation Engineering, Vol.15, No.2, 286-294, 2007.
Smith, S.L. et. al. “The Application of Evolutionary Algorithms towards the Diagnosis of Parkinson's Disease,” GECCO Workshop on Medical Applications of GEC, Seattle, July, 2006.
Allen, D.P., Halliday, D.M., Smith, S.L., Playfer, J. & Aly, N. "A clinical diagnostic tool for the assessment of bradykinesia in Parkinson’s disease using using low cost computer peripherals," Institute of Physics and Engineering in Medicine, Annual Scientific Meeting, 34, 2005.
Intelligent Control in Practice

Members: Yoshikazu Hirayama
The Shaky Hand was devised as a generic technology demonstrator and was modelled on a village fete game. In the original game, the aim is to guide, by hand, a wire loop along a wiggly wire from one end to another, without touching the loop to the wire. The loop used in the Shaky Hand, however, is guided by a plotter type arrangement with x and y translational drive motors and is rotated by a third motor. A way of providing dependable control of Shaky Hand using intelligence to react to the failure of subsystems has been established using Cartesian Genetic Programming (CGP). The development of control algorithms with fault tolerance allows robust control in a reliable framework, utilising appropriate redundancy without squandering available computing resources. Successful results have been obtained in Practice. Embodiment problems are overcome. Development of more sophisticated direct control methods are being investigated at moment.
Multi-Agent Intelligent Control for the Skylon Launch Vehicle

Members: Peter Mendham, Yoshikazu Hirayama
Skylon is a Single Stage to Orbit (SSTO) fully reuseable launch vehicle currently being developed by Reaction Engines Limited in collaboration with two Italian aerospace companies Avio SpA and ELV SpA. The University of York has been heavily involved with dynamic modelling of both the vehicle aerodynamics and the engines (see the separate SABRE engine project) for the past five years. Skylon is intended to be fully autonomous and therefore requires highly intelligent, robust and reliable control systems. This project is using Multi-Agent System (MAS) as a novel paradigm for intelligent control. The use of multiple intelligent agents allows robust control in a reliable framework, utilising appropriate redundancy without squandering available computing resources.
Biosequence Motif Discovery using Evolutionary Computation

Members: Michael Lones, Andy Tyrrell Start Date: June 2006
We have developed an evolutionary algorithm based system for identifying regulatory motifs in the promoter regions of genes. Evolutionary algorithms provide an interesting approach for motif discovery problems since they offer both a global approach to search and flexibility in terms of representation and scoring function. Arguments along these lines can be found in this review paper:
The Evolutionary Computation Approach to Motif Discovery in Biological Sequences
M. A. Lones and A. M. Tyrrell, Proc. Workshop on Biological Applications of Genetic and Evolutionary Computation (BioGEC),
GECCO2005, June 2005.
In our initial approach, we used within-population data clustering to promote search for multiple, diverse, transcription factor binding sites. Details are available in this paper:
Regulatory Motif Discovery Using a Population Clustering Evolutionary Algorithm [PDF] [link]
M. A. Lones and A. M. Tyrrell, IEEE/ACM Transactions on Computational Biology and Bioinformatics 4(3):403-414, July-September 2007.
We are currently looking at how co-evolution may be used to search for transcription factor binding sites and higher order regulatory motifs (such as cis-regulatory modules) in parallel. Our initial results suggest that this approach promotes search for weakly conserved transcription factor binding sites in long promoter sequences. Details appear in this paper:
A Co-Evolutionary Framework for Regulatory Motif Discovery
M. A. Lones and A. M. Tyrrell, Proc. IEEE Congress on Evolutionary Computation, September 2007.
nEUro-IT.net Research Directory
Members: Michael Lones, Andy Tyrrell
The aim of nEUro-IT.net, the EU Neuro-IT Network of Excellence, is to build a critical mass of new interdisciplinary research excellence at the interface between neuroscience, information technology and engineering. As part of this initiative, we maintain a database of people, organisations, applications and funding opportunities within the nEUro-IT.net remit.
Cartesian Genetic Programming (CGP)
Members: Julian Miller, Steve Smith, David Halliday, Andy Tyrrell, Tim Clarke, Janet Clegg, Michael Lones, James Alfred Walker, Martin Trefzer, James Hilder, Tuze Kuyucu, Gul Muhammad Khan, Katharina Voelk
Start Date: October 2003
CGP Overview
CGP was originally developed by Julian Miller and Peter Thomson for the purpose of evolving digital circuits. It represents a program as a directed graph (that for feed-forward functions is acyclic). The benefit of this type of representation is that it allows the implicit re-use of nodes, as a node can be connected to the output of any previous node in the graph, thereby allowing the repeated re-use of sub-graphs. This is an advantage over tree-based GP representations where identical sub-trees have to be constructed independently. The CGP technique shares some similarities with Riccardo Poli's Parallel Distributed GP, as the techniques were independently developed at the same time. Originally, CGP used a program topology defined by a rectangular grid of nodes with a user defined number of rows and columns. However, later work by Tina Yu and Julian Miller showed that it was more effective when the number of rows is chosen to be one.
In CGP, the genotype is a fixed length representation consisting of a list of integers which encode the function and connections of each node in the directed graph. However, CGP uses a genotype-phenotype mapping that does not require all of the nodes to be connected to each other, this results in the program (phenotype) being bounded but having variable length. Thus there may be genes that are entirely inactive, having no influence on the phenotype, and hence the fitness. Such inactive genes therefore have a neutral effect on genotype fitness. This phenomenon is often referred to as neutrality. The influence of neutrality in CGP has been investigated in detail by Julian Miller, Vesselin Vassilev, and Tina Yu, and has been shown to be extremely beneficial to the efficiency of evolutionary process on a range of test problems.
CGP Extensions
The following extensions to CGP have been developed by members of the Intelligent Systems Group:
- Embedded and Modular CGP (James Walker and Julian Miller) allows the automatic acquisition, evolution and re-use of subroutines in CGP and has been shown to improve the performance of the technique on modular problems.
- Multi-chromosome CGP (James Walker and Julian Miller) allows the decomposition of a large multiple output problem into a series of smaller single output problems. This has the affect of reducing the complexity of the problem and making it easier to solve.
- Real-valued CGP (Janet Clegg, James Walker and Julian Miller) incorporates ideas from real-valued Genetic Algorithms with CGP. This introduces a real-valued genotype and an extra level of neutrality into the CGP representation, and also a crossover operator which appears to be beneficial to evolution.
- Implicit-context CGP (Steve Smith and Michael Lones) introduces implicit context representation to CGP, a concept which was first developed in our work on the enzyme genetic programming system, and which enables positional independence and improved recombination.
- Self-modifying CGP (Julian Miller and Simon Harding) is a developmental form of CGP which allows the phenotype to change over time using a series of iterative self-modification operations.
Applications of CGP
CGP and the extensions to CGP have also been applied to a number of applications within the Intelligent Systems Group.
- Evolving Helicopter Flight Controllers (Tim Clarke, Julian Miller and Omar Hobohm)
- Co-evolving Neuro-developmental Programs for Playing Checkers (Julian Miller, David Halliday and Gul-muhammad Khan)
- Evolving Multiple CGP Networks for the Analysis of Mammograms (Steve Smith and Katharina Voelk)
- Evolving Portrait Painters (Julian Miller, James Walker and Steve DiPaola)
- Evolving Classification Systems for Processing Medical Data (Steve Smith and Michael Lones)
Implicit Context Representation for Evolutionary Computation
Members: Michael Lones, Andy Tyrrell, Steve Smith
Start Date: October 2000
Implicit context is a novel approach to representing evolving structures in which structural components describe their interactions using functional descriptions of other components. In conventional structural representations, these interactions are described using positional information. However, positional information is not generally conserved between solutions and between generations, leading to disruptive effects when genetic operators are applied. This can be seen in genetic programming, where sub-tree crossover does not typically carry out useful behaviour. Enzyme genetic programming is a form of genetic programming which uses implicit context representation, and has shown behavioural and performance benefits when applied to a range of problems. More recently, we have also shown how implicit context may be implemented within cartesian genetic programming. Application domains include digital circuit design, image filter design, and finite state automata induction.
Recent Publications
Positional Independence and Recombination in Cartesian Genetic Programming
X. Cai, S. L. Smith and A. M. Tyrrell, European Conference on Genetic Programming (EuroGP), LNCS 3905:351-360, 2006.
An Implicit Context Representation for Evolving Image Processing Filters
S. L. Smith, S. Leggett and A. M. Tyrrell, EvoWorkshops2005, LNCS 3449:407-416, 2005.
Enzyme Genetic Programming: Modelling Biological Evolvability in Genetic Programming
Michael Adam Lones, Ph.D. Thesis, Department of Electronics, University of York, 2004.
Modelling Biological Evolvability: Implicit Context and Variation Filtering in Enzyme Genetic Programming
M. A. Lones and A. M. Tyrrell, BioSystems 76(1-3):229-238, August-October 2004.